Tkinter How to Save Upload File as Dataframe
Pandas (PANel Information Analysis) is a popular library when it comes to data assay and machine learning. Pandas library is built on top of Numpy. It is very complex to handle data in Numpy before the evolution of the pandas' Data frame. Numpy is a matrix array that does indexing like 0, 1, 2, 3…… This makes it hard to call columns based on the index.
For example, you lot want to fetch information of the country cavalcade (column no 5) in a given data file. So, yous demand to remember column number (index 4) ever in case y'all are using Numpy.
Merely, with the emergence of the pandas' Data frame, indexing is done based on the column name (or custom index). So, it becomes easy to fetch data based on column names like "land". The analyst does not demand to remember the index like 0, one, 2. This is the benefit of the pandas' data frame. Pandas' data frame besides offers the below benefits:
- Solves the usability of the Numpy problem.
- It can read, write information in CSV, text, excel, and JSON formats.
- Information technology provides fast and efficient data manipulation.
- It can handle incomplete or missing data.
Pandas offering two types of data sets. Get-go is "Series" is a one-dimensional array and this also solves the index consequence of Numpy. The second is "Data Frame" which is a two-dimensional tabular format data structure.
Allow'south meet how a custom index can exist defined in the series data set. In that location are ii lists of countries and capitals. Series tin be created with these ii lists. The first annunciation sets the default index as Numpy. The second declaration shows how to define a custom index as "countries". So now capitals information will take a custom index as countries tin be accessed as well.
import numpy every bit np
import pandas every bit pd
countries= [ 'India' , 'USA' , 'Qatar' ]
capitals= [ 'New Delhi' , 'Washington DC' , 'Doha' ]
pd.Series (data=capitals)
custom_series=pd.Series (data=capitals,alphabetize=countries)
custom_series[ 'Qatar' ]
This is the beauty of pandas information structure as you can accessing data based on a custom alphabetize similar custom_series['Qatar'] instead of accessing data with a default index like [0], [ii]. This is why the pandas library has go a favorite of data engineers, scientists, and machine learning guys.
Now, the limitation of Series is that it is one dimensional. But, in the real earth, we want data in a two-dimensional format. So, the answer is Data Frames. Let's motility on to Data Frames. Data Frames stores any data types like int, cord, float, boolean in tabular format. It offers a lot of mathematical functions and flexibility. Let's see how data frames wait like:
import pandas equally pd
people_list= [ [ 'Roni' , 'O+' , 60 ] , [ 'Summon' , 'A+' , 45 ] , [ 'Montu' , 'B+' , 15 ] , [ 'Beth' , 'A+' , 25 ] ]
people_df=pd.DataFrame (people_list,columns= [ 'Proper noun' , 'Blood group' , 'Age' ] )
people_df
Output:
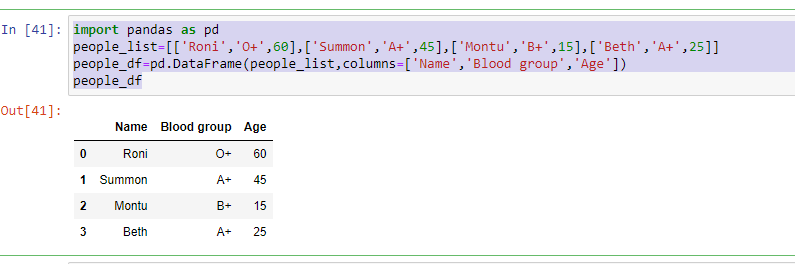
Here, y'all tin meet the cavalcade proper noun appears on height of each column as Name, Blood group, Age instead of 0,1,ii.
Every bit an annotator, you want to fetch just the Name from this data set as of at present. So, you are not required to recollect the position of the column whether Name is stored on the second or tertiary column. You only have to provide the name of the custom index. Nobody wants to remember the numbers. Correct? Remembering a custom name is always easy for everyone. This is the do good and flexibility that Data Frames provide.
Output:
0 Roni
1 Summon
2 Montu
3 Beth
So, this is all basics of data structures of pandas. A question may arise in your heed that we deal with huge information in the existent world. Right? The data volition non exist e'er every bit small as we have seen now in form of lists. There must be a big text file, CSV files, or excel files where information resides. That information should exist uploaded in Data Frames for further study. How to upload that big data file?
There are unlike file formats such every bit CSV, text file, excel file, JSON file. We will see at present how to upload data from different file formats.
1. Uploading a CSV file:
: The CSV files are comma-separated files. Suppose, we have a sample CSV file as below and want to upload information technology. This sample file is stored on the given GitHub URL. Y'all can choose any URL or your GitHub URL where the file is kept. Read_csv is the method to upload CSV file.
import pandas as pd
csv_datafr=pd.read_csv ( 'URL' )
print (csv_datafr)

2. Uploading a JSON file:
JSON file format is pop every bit this is non dependent on the device. The JSON file format information tin exist handled on any device similar android phones, iOS. Read_json is the function to upload JSON files. The sample JSON file is equally below:

Beneath is the syntax to upload JSON file.
import pandas as pd
json_datafr=pd.read_json ( 'URL' )
json_datafr
Output:

three. Uploading an Excel file:
Excel is as well a source of huge data. The pandas library provides a read_excel method to upload an excel file. There is a parameter "sheet_name" which holds the sail number which should be uploaded. For instance, you desire to upload the information of the first canvas of an excel then sheet_name will agree value 0. For the 2d canvass data upload, sheet_name will agree value 1.

y'all can utilise the beneath code:
excel_datafr=pd.read_excel ( 'URL' ,sheet_name= 0 )
excel_datafr

iv. Uploading a text file:
The method to upload a text file is the same as a CSV file merely you lot need to provide sep parameter. The sep parameter stands for the separator of the text file. The column data is separated using either semi-colon (;) or comma (,) in a single row. The sep parameter will explain to pandas which separator is used in a text file for different columns.
text_datafr=pd.read_csv ( 'URL' ,sep= ';' )
text_datafr
The data is by and large uploaded using a URL. Nevertheless, you tin can upload information from the local machine as well. The data file should be placed inside the binder where the jupyter notebook is installed if you are using a jupyter notebook. If you lot are using some other IDE then your information files should be placed inside the folder where IDE is installed.
You can provide the path of your data file as well and provide the path instead of URL in the given method. This tin exist done using sample lawmaking as below :
path= "C:\Users\Swapnil\50ocaltext4.txt" #requite your ain local path
csvlocal_datafr=pd.read_csv(path, sep=',')
csvlocal_datafr
Pandas library also provides related methods to explore more than nearly uploaded data. Suppose you want to merely take a await at uploaded information whether it is uploaded correctly or not. In this case, there is no need to print the entire data frame, you lot can use the caput method to go the first five rows.
Dataframe_variable.head ( )
Similarly, the info method volition provide the data regarding information type, values of not-naught, or null value in a given column so that y'all tin can trace the count of missing values.
Dataframe_variable.info ( )

The result set as the to a higher place output screen will be displayed. There are many more functions and attributes like Shape and count to know the dimension and count of records.
Y'all have seen how to upload files in pandas' information frame. Information technology is recommended to explore more using references to other articles and documentation. I hope you enjoyed uploading data into Information frames and setting custom dimensions.
Proceed exploring more!
Source: https://codeforgeek.com/pandas-data-frames-and-uploading-files/
0 Response to "Tkinter How to Save Upload File as Dataframe"
Post a Comment